A fresh Reddit debate has pulled METR's time-horizon benchmark back into the center of the AI argument. The issue is not whether agents are improving, but whether one famous graph can carry the weight investors, founders and policymakers have put on it.
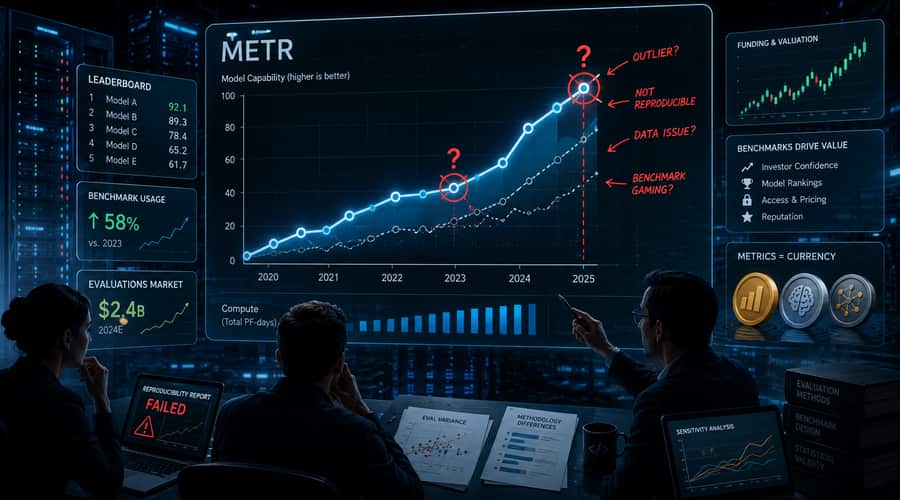
The most important chart in AI is having another credibility test. A critique of METR's widely cited time-horizon work resurfaced on r/MachineLearning on Monday, bringing fresh attention to an older but still unresolved complaint: the graph may look clean, but the assumptions underneath it are anything but simple.
That matters because the METR chart has travelled far beyond evaluation circles. It has become shorthand for a bigger claim about autonomous AI agents, namely that models are rapidly gaining the ability to complete longer and longer tasks without human help. Investors use that idea to think about labor replacement. Product teams use it to justify agent roadmaps. Safety researchers use it to frame risk timelines. When a benchmark becomes part of the market's operating language, flaws in the benchmark do not stay academic.
According to METR's own time-horizon page, last updated May 8, 2026, the metric estimates the human task duration at which an AI agent is predicted to succeed at a given reliability level, usually 50% or 80%, across more than a hundred software-heavy tasks. METR also says clearly that this is not the literal amount of time an AI can work independently. It is a measure of task difficulty, calibrated against how long a human expert might take.
That distinction is doing a lot of work. A 2-hour time horizon does not mean an agent can safely be handed any 2-hour office task. It means the model is estimated to have a certain success probability on a task that took a low-context human roughly that long in a controlled setup. Those are different things, and the gap between them is where a lot of business hype gets created.
The renewed debate traces back to Nathan Witkin's essay in Transformer, which argues that METR's Long Tasks benchmark is too compromised to support broad claims about AI replacing software work. The critique focuses on several pressure points: human baselines, task realism, statistical modeling and the way headline trend lines are communicated outside the paper.
The human baseline issue is especially important. METR's own materials acknowledge that its contractors are often working with much less context than professionals doing similar work in their regular jobs. That can inflate task duration, which then makes the AI's apparent time horizon look more impressive. If a task is labelled as taking hours because the human first had to understand an unfamiliar codebase, it is not the same as saying a working engineer needed those hours in a real company setting.
METR has not ignored these limitations. In January, one of the main authors wrote that many people overstate the precision of the time-horizon measurements and draw conclusions the evidence does not fully support. In March, METR published a note on modeling assumptions and said a regularization mistake had been fixed, reducing recent models' 50% time-horizon estimates by up to 20%. The same note said reasonable alternative fits could reduce recent 50% estimates by up to 35%, while increasing 80% estimates by as much as 100%.
That is not a small footnote. It means the benchmark is sensitive to choices that most readers of the graph never see. The core direction may still be right, but the exact curve is less solid than the chart's authority suggests.
Why this matters for the AI business
Startups do not raise money on confidence intervals. They raise money on narratives. The time-horizon story has been useful because it gives founders a simple way to explain why agents will soon take over larger chunks of software engineering, research and operations work. If the line keeps doubling, the pitch writes itself.
But enterprise buyers think in failure modes, not just averages. A model that succeeds half the time on a controlled software task is not automatically ready for finance workflows, legal reviews, infrastructure changes or customer-facing decisions. Some work only becomes automatable when reliability is near 98% or 99%, and METR itself has said much larger benchmarks would be needed to measure those levels well.
This is where the market needs to be more disciplined. Benchmarks can point to a trend, but they cannot replace internal testing. A company deciding whether to deploy an AI coding agent should care less about a public curve and more about its own repositories, security rules, review process, incident history and tolerance for bad changes. A benchmark built from self-contained tasks can help frame the question. It cannot answer it alone.
The same applies to regulation. Policymakers want simple signals because capability growth is hard to measure. METR's work is valuable partly because it tries to translate model performance into something human beings understand. But a metric that depends heavily on task selection, human baselines and modeling choices should not become a single dial for deciding when a system is dangerous.
As of Monday, there was no visible new METR correction specifically tied to the Reddit discussion. The practical response is already in METR's own caveats: the benchmark is useful, but narrow, noisy and easy to misread. The next phase of AI evaluation will need more realistic tasks, better human comparisons and clearer communication about uncertainty. Until then, the famous graph should be treated as a signal, not a clock counting down to full automation.
Also read: ClickUp's layoffs show AI is rewriting productivity software. • Palantir turns a London police setback into a public test of AI procurement • MiniCPM5-1B makes small AI models harder for startups to ignore


